Core Idea
Learn time as a bridge, not just a sequence
Jointly encode the start and end observations, then predict the latent visual evolution in between.
CVPR 2026
1 Forschungszentrum Jülich, 2 RWTH Aachen University
TLDR: TimeBridge extends iBOT for video representation learning by reconstructing intermediate frames from temporally separated start and end frames.
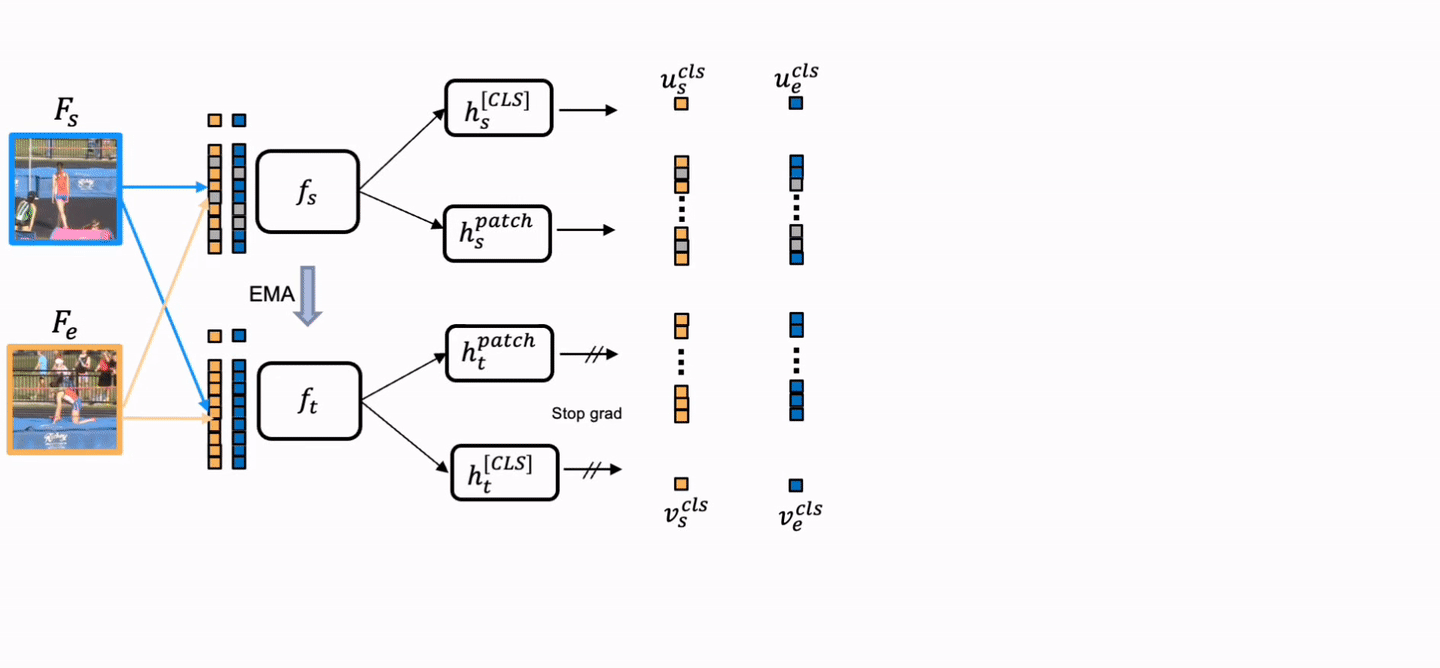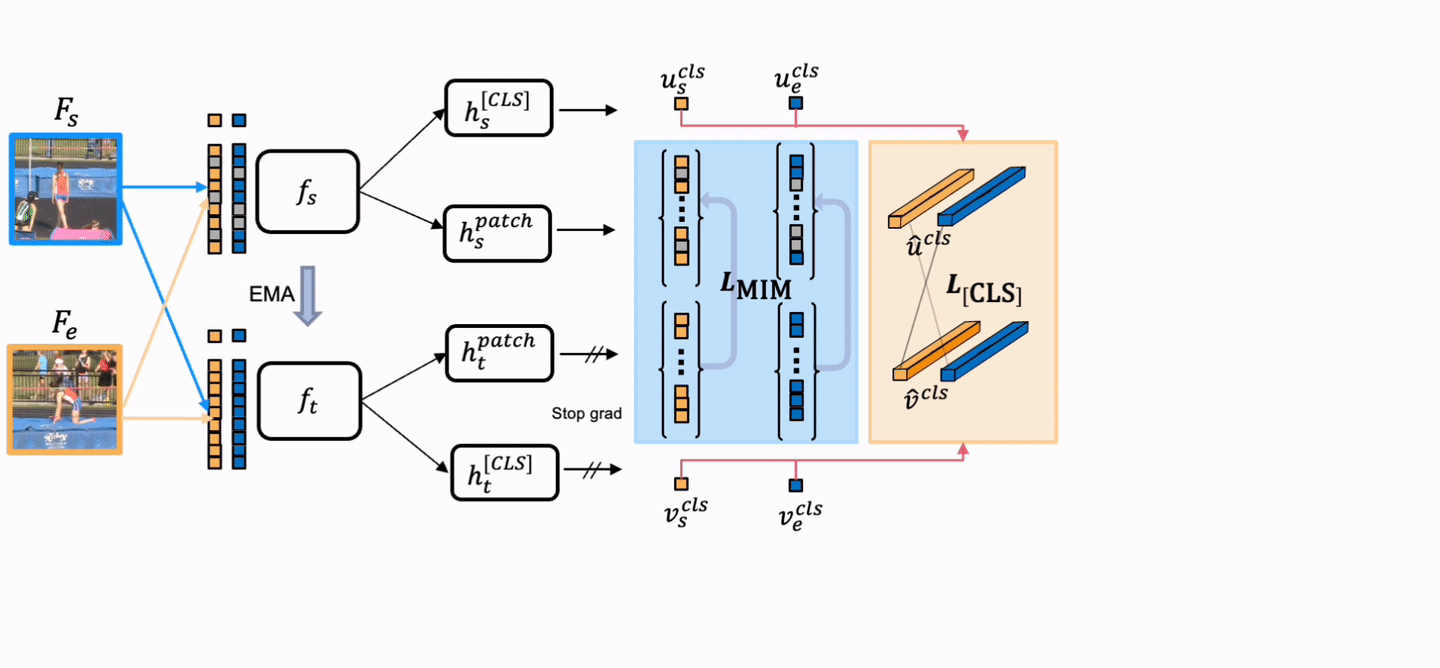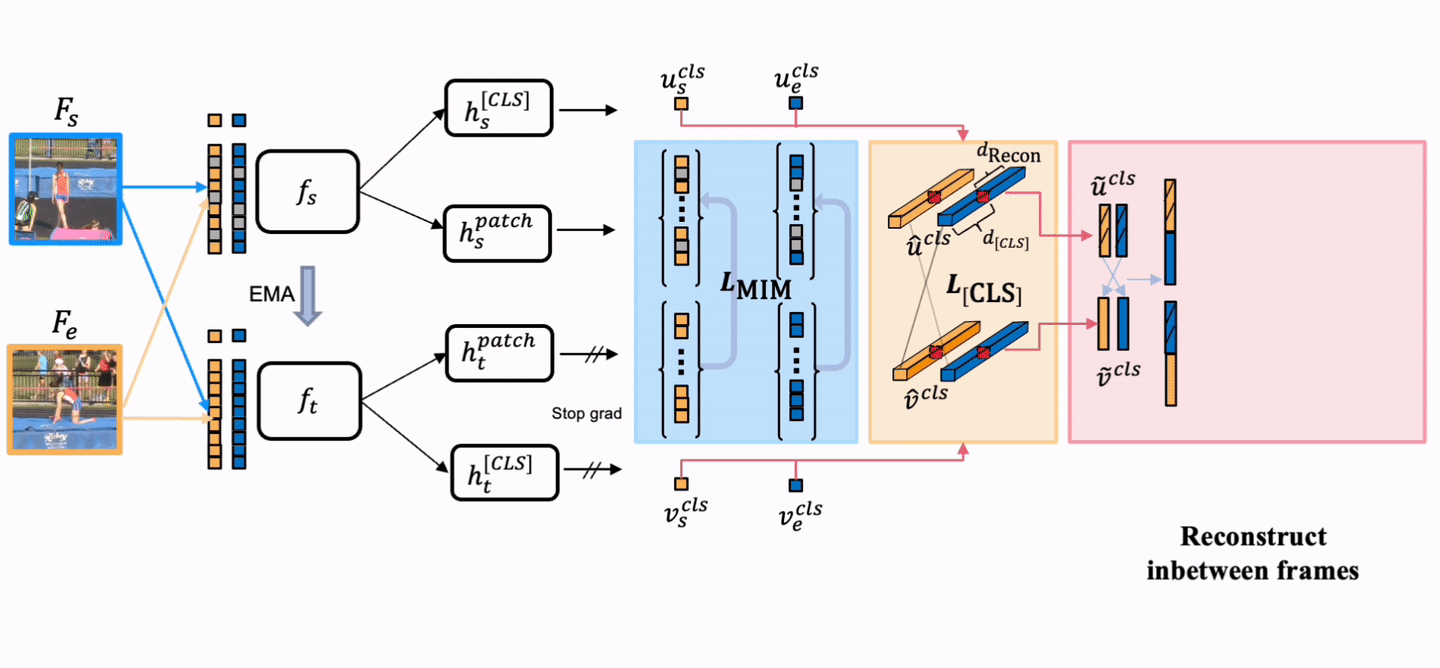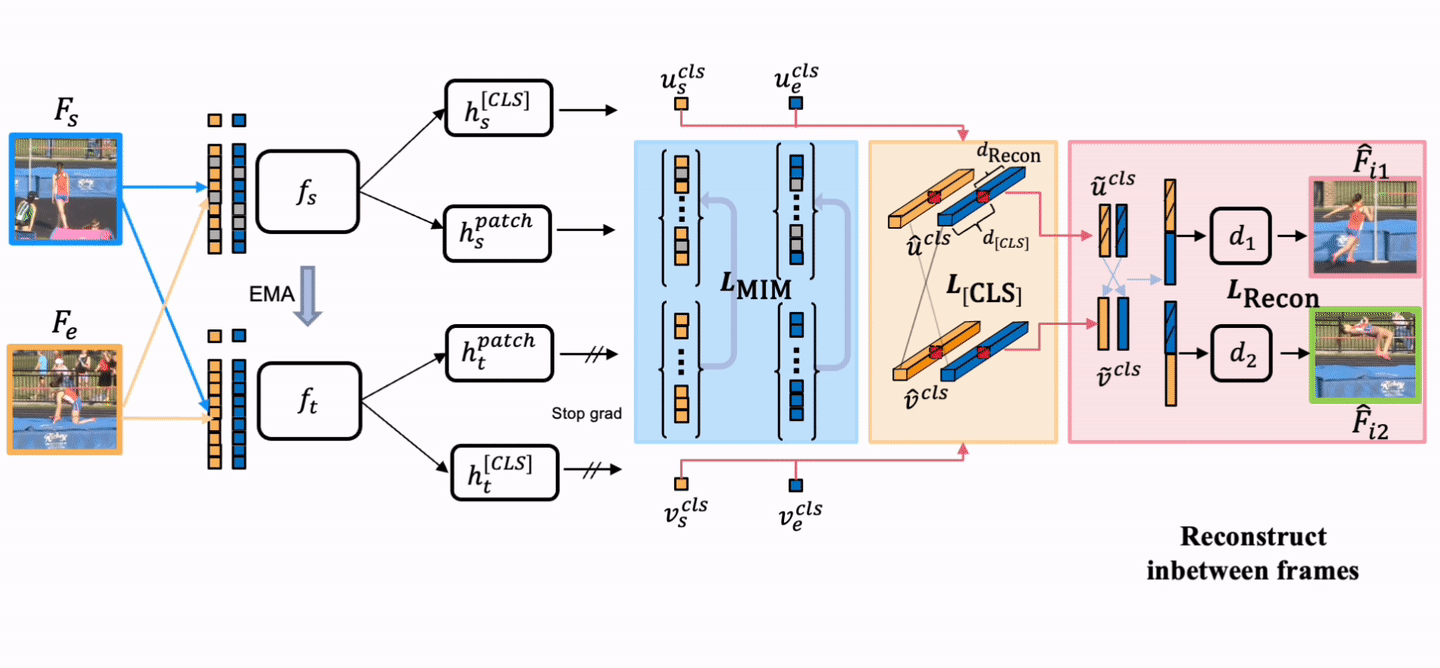
Overview
TimeBridge is a self-supervised video representation learning method that models how visual content evolves between a start frame and an end frame. It learns temporal transformations by reconstructing in-between frames, producing stronger motion-aware features for dense video prediction tasks such as video object segmentation and part propagation.
Core Idea
Jointly encode the start and end observations, then predict the latent visual evolution in between.
Representation Benefit
The learned features reflect how objects change over time, making them strong for dense propagation tasks.
Downstream Impact
The representation transfers to video object segmentation and semantic or part propagation benchmarks.
Results
Performance comparison on DAVIS 2017, VIP, and JHMDB.
| Method | Backbone | Dataset | Epoch | DAVIS | VIP | JHMDB | |||
|---|---|---|---|---|---|---|---|---|---|
| J & Fm | Jm | Fm | mIoU | PCK@0.1 | PCK@0.2 | ||||
| DINO | ViT-S/16 | ImageNet | 800 | 61.8 | 60.2 | 63.4 | 36.2 | 45.6 | 75.0 |
| iBOT | ViT-S/16 | ImageNet | 800 | 62.8 | 61.2 | 64.5 | 37.9 | 44.6 | 74.6 |
| CrOC | ViT-S/16 | ImageNet | 300 | 44.7 | 43.5 | 45.9 | - | - | - |
| VideoMAE | ViT-S/16 | Kinetics | - | 39.3 | 39.7 | 38.9 | 23.3 | 41.0 | 67.9 |
| SiamMAE | ViT-S/16 | Kinetics | 2000 | 62.0 | 60.3 | 63.7 | 37.3 | 47.0 | 76.1 |
| SiamMAE | ViT-S/16 | Kinetics | 400 | 57.9 | 56.0 | 60.0 | 33.2 | 46.1 | 74.0 |
| CropMAE | ViT-S/16 | Kinetics | 400 | 58.6 | 55.8 | 61.4 | 33.7 | 42.9 | 71.1 |
| CropMAE | ViT-S/16 | INSub | 400 | 60.4 | 57.6 | 63.3 | 33.3 | 43.6 | 72.0 |
| RSP | ViT-S/16 | Kinetics | 400 | 60.1 | 57.4 | 62.8 | 33.8 | 44.6 | 73.4 |
| T-CoRe | ViT-S/16 | Kinetics | 400 | 64.7 | 63.5 | 66.0 | 37.8 | 47.0 | 75.2 |
| Ours | ViT-S/16 | Kinetics | 400 | 66.2 (+1.5) | 64.3 (+0.8) | 68.1 (+2.1) | 39.4 (+1.5) | 45.8 | 74.0 |
| DINO | ViT-S/8 | ImageNet | 800 | 69.9 | 66.6 | 73.1 | 39.5 | 56.5 | 80.3 |
| SiamMAE | ViT-S/8 | Kinetics | 2000 | 71.4 | 68.4 | 74.5 | 45.9 | 61.9 | 83.8 |
| Ours | ViT-S/8 | Kinetics | 100 | 72.4 | 69.6 | 75.2 | 44.1 | 57.6 | 81.0 |
| Ours | ViT-S/8 | Kinetics | 400 | 73.5 (+2.1) | 70.6 (+2.2) | 76.5 (+2.0) | 47.5 (+1.6) | 59.2 | 82.6 |
Empty entries indicate that no result was reported in the corresponding publication. Values in parentheses denote the gains highlighted in the paper.
Qualitative Comparison
Three qualitative comparison clips from the DAVIS 2017 object segmentation propagation benchmark.
Qualitative comparison sequence from the supplementary material.
Qualitative comparison sequence from the supplementary material.
Qualitative comparison sequence from the supplementary material.
Citation
@InProceedings{Wang_2026_CVPR,
author = {Wang, Qin and Morrison, Abigail and Scharr, Hanno and Krajsek, Kai},
title = {TimeBridge: Self-Supervised Video Representation Learning via Start-End Joint Embedding and In-Between Frame Prediction},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {39647-39658}
}